Retrieval Augmented Generation
RAG
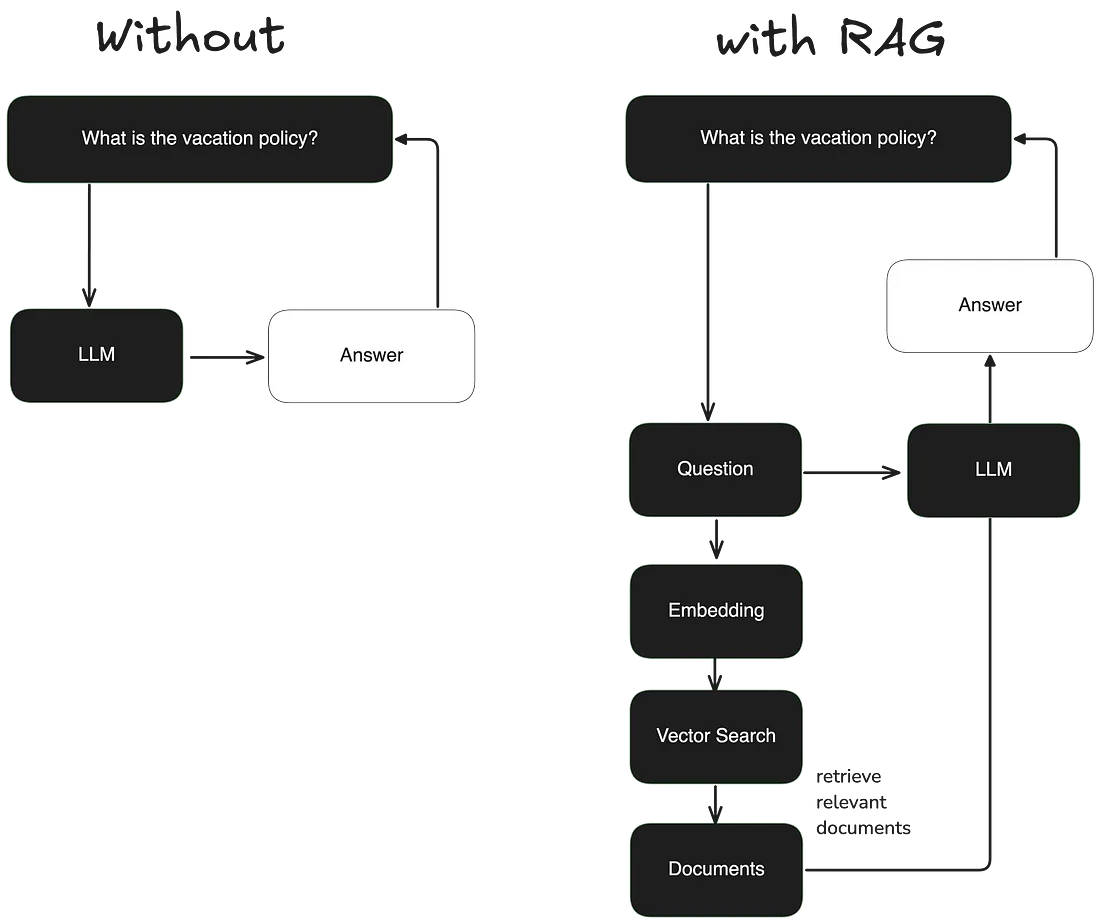
Retrieval Augmented Generation, or "RAG", is an informatic tool that enables a Large Language Model (LLM) to "retrieve" information from a Knowledge Base.
In other words, you can use Natural Language Processing (normal words) to ask questions of the AI (LLM) and the LLM will pull information from a knowledge base to answer questions.
Library Analogy
Using RAG is like going to the library with a question. You bring your question to the librarian (the LLM) who goes and pulls the best books and identifies the best chapters/quotes to answer your question. The librarian then compiles the information in a way that best answers your question, "generating" a response.
The library in this case can be any Knowledge Base; articles, youtube videos, personal notes, company data, etc.
Key Elements Of RAG
Chunking: splitting the text into segments, standalone units that retain context
Embeddings: organizing the chunks based on their relevance to each other, aka based on similarity
Vector Database: stores the embeddings, creating a database that can be searched based on context, not just exact matches
- LLM breaks up your question into chunks to compare it against the existing database
- Database sends answer chunks to LLM based on similarity to what it has in its system
- LLM is the synthesizer that pieces the retrieved chunks together in a way that makes sense to answer the question
Graphic from: https://medium.com/google-cloud/google-cloud-rag-api-c7e3c9931b3e